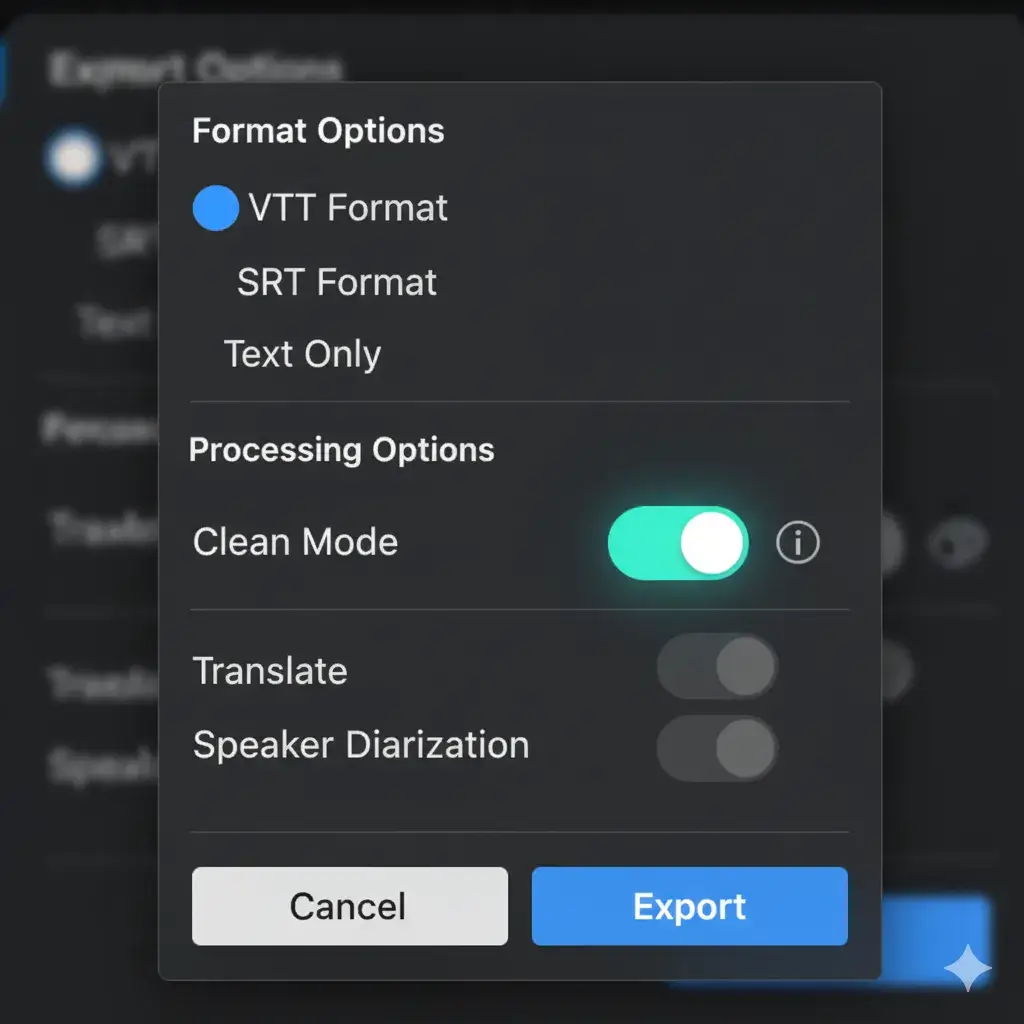
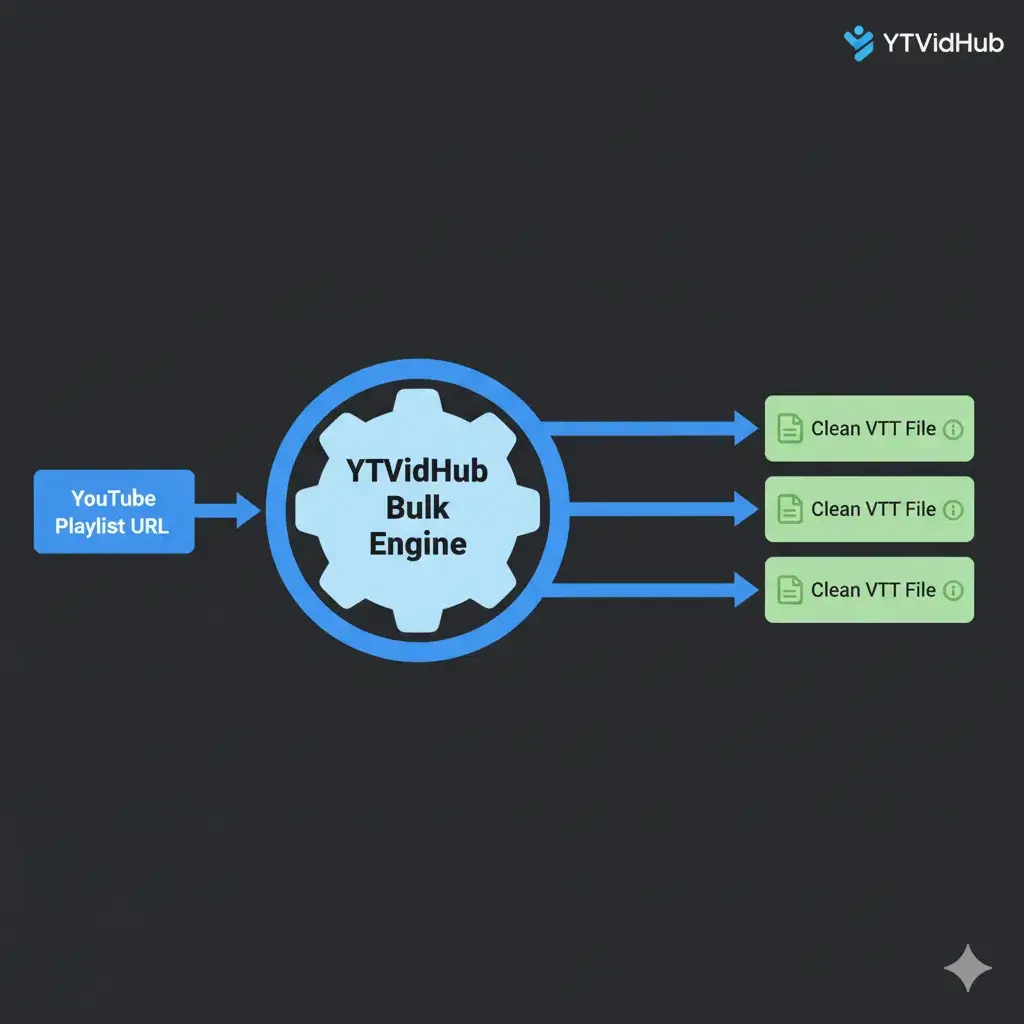
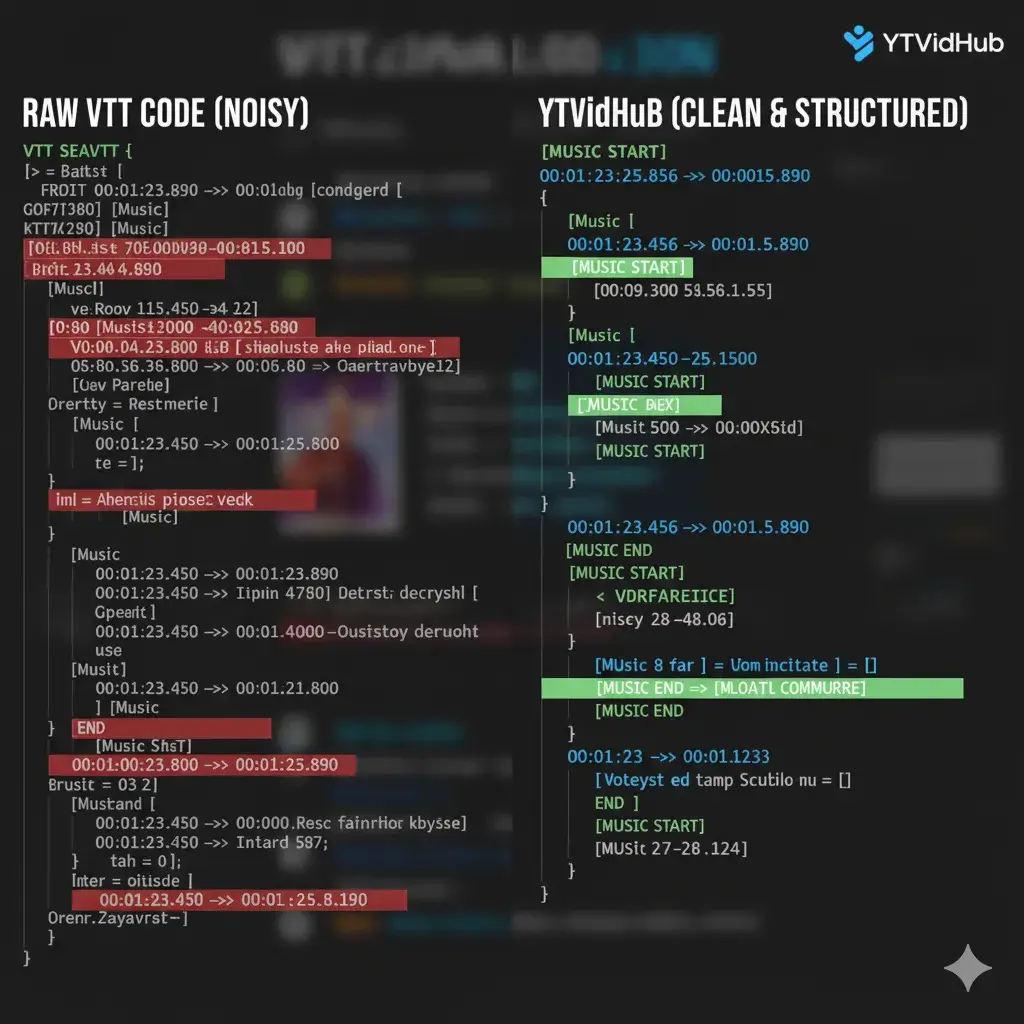
1. The VTT Data Quality Crisis
The standard WebVTT (.vtt) file downloaded from most sources is toxic to a clean database. It contains layers of metadata, timecodes, and ASR noise markers that destroy the purity of the linguistic data.
WEBVTT
Kind: captions
Language: en
1:23.456 --> 1:25.789 align:start position:50%
[Music]
1:26.001 --> 1:28.112
>> Researcher: Welcome to the data hygieneYour time is the most expensive variable in this equation. If you are still writing regex scripts to scrub this debris, your methodology is inefficient. The solution isn't better cleaning scripts; it's better extraction.
Real-World Performance Data
"On a corpus of 50 technical conference talks, raw files required 5.1s per file for scrubbing. YTVidHub's clean output dropped this to 0.3s—a 17x throughput gain allowing for datasets 5x larger in the same timeframe."