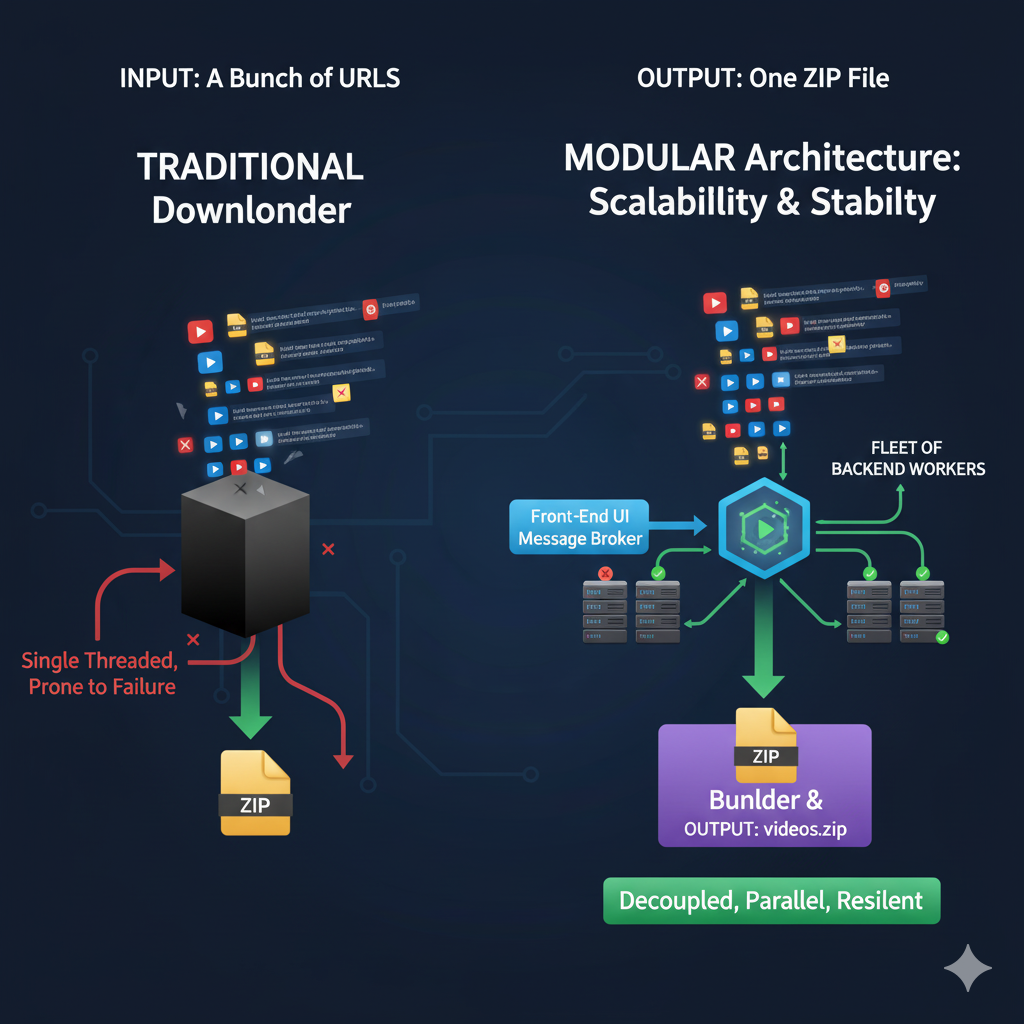
When we introduced the concept of a dedicated Bulk YouTube Subtitle Downloader, the response was immediate. Researchers, data analysts, and AI builders confirmed a universal pain point: gathering transcripts for large projects is a "massive time sink."
This is the story of how community feedback and tough engineering choices shaped YTVidHub.