Engineering Blog
Building a YouTube Subtitle Pipeline: Architecture Decisions & Lessons
The architectural decisions behind YTVidHub's bulk YouTube subtitle downloader — from queue design to clean TXT export for LLM pipelines.
By YTVidHub Engineering | Updated Oct 26, 2025
When we introduced a dedicated bulk YouTube subtitle downloader, user feedback was immediate: collecting transcript data at scale was still too manual and fragile.
This write-up covers the engineering choices that addressed reliability, throughput, and data usability.
1. Scalability Meets Stability
Bulk subtitle extraction is not only about speed. It requires predictable behavior under bursty loads and partial failures.
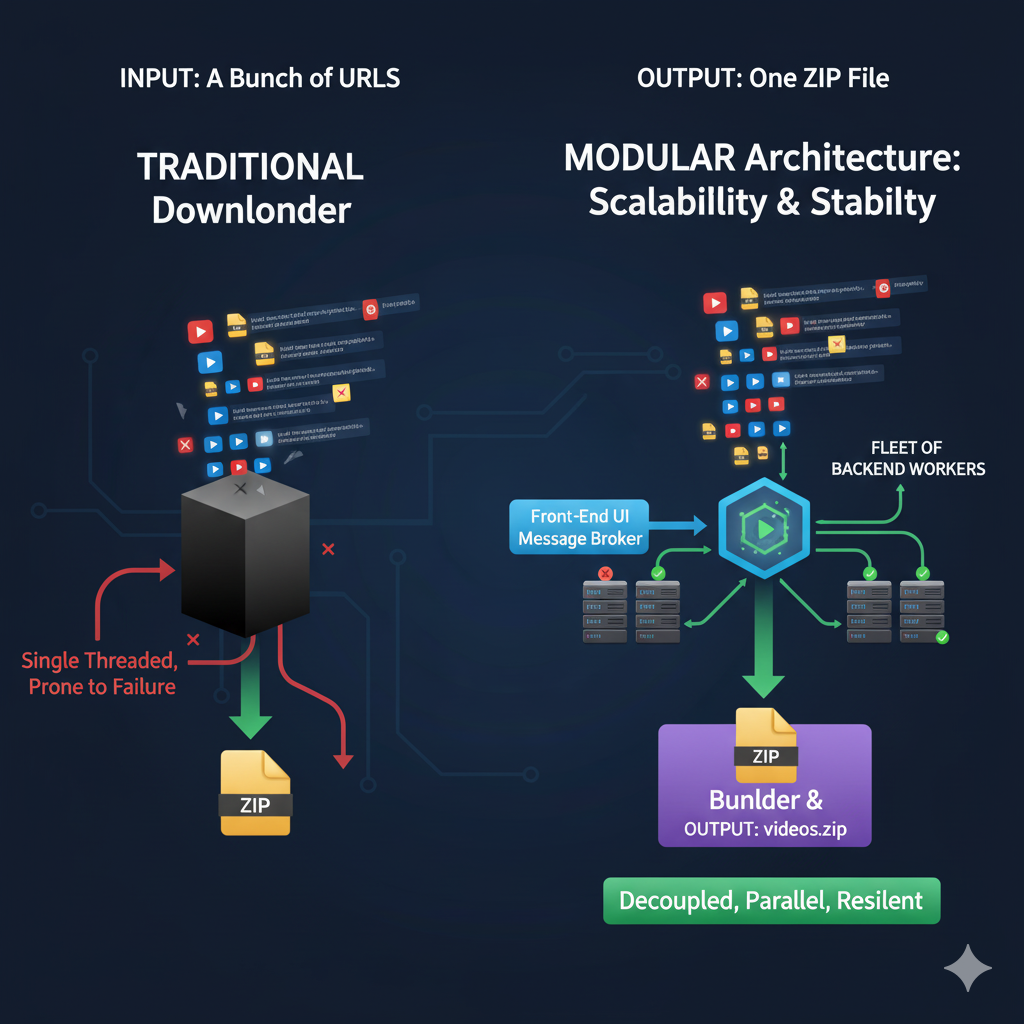
Figure 1: Decoupled backend workers with queue-based orchestration.
We use an asynchronous queue and worker fleet. Client requests push video IDs into a broker; workers fetch jobs independently and run in parallel. This isolates faults and avoids all-or-nothing failure behavior.
2. Data: More Than SRT
Raw SRT often behaves like dirty data for analysis tasks. It carries timing scaffolding and formatting that add cleanup overhead.
“I just need clean text for model input. Writing another cleanup script for every batch wastes time.”
That feedback changed the roadmap. We treated clean TXT output as first-class and added a dedicated cleaning stage for timestamp and metadata removal.
3. The Accuracy Dilemma
Auto-generated captions provide baseline coverage but can underperform on specialized or multilingual content. Our strategy runs in phases.
Phase 1: Live Now
Free Baseline Data
Unlimited bulk downloads of official YouTube subtitle tracks (manual + ASR) with fast queue execution.
Phase 2: In Development
Pro Transcription
- • OpenAI Whisper integration
- • Context-aware correction signals
- • Silent-segment removal
Bulk YouTube Subtitle Downloader Architecture
This engineering guide focuses on bulk YouTube subtitle downloader architecture, queue reliability, and scalable transcript processing. Technical readers usually care less about UI features and more about retry strategy, fault isolation, and predictable throughput.
The system has three important proof points: asynchronous queue orchestration, clean TXT data shaping, and accuracy trade-offs for ASR tracks. These are the elements that usually decide whether a subtitle pipeline can be trusted in high-volume analytics or model-ingestion workflows.
We also position this content as a bridge between product and engineering audiences: practical architecture language for builders, with enough operational context for content and research teams.
Operational Lessons From Production
- Keep retry logic idempotent to prevent duplicate exports.
- Separate queue health metrics from transcript quality metrics.
- Store clean-text and timed-text outputs together for traceability.
- Surface partial-failure states clearly so users can recover fast.
Retry, Idempotency, and Failure Budget
For high-volume subtitle jobs, retries are inevitable. The key design rule is idempotency: repeating the same job should not create duplicate exports or inconsistent result states. We enforce this by hashing job inputs, storing deterministic output keys, and applying completion guards before write operations.
We also operate with a failure budget mindset. Not every external caption fetch error should page the team, but repeated upstream failures in a region or language group should trigger degradation mode and user-visible notices. This keeps reliability honest while avoiding alert fatigue.
In practice, this approach reduces hidden data corruption risk and improves trust for users who rely on predictable batch outcomes.
Observability Metrics That Matter
Queue Metrics
- Time-to-start per job batch
- Retry rate by source and language
- Worker saturation and wait depth
Data Quality Metrics
- Transcript completeness ratio
- Noise density in clean TXT output
- Low-confidence segment concentration
Why This Matters for Content Systems
Reliable subtitle infrastructure is not only an engineering win. It directly affects content velocity, update freshness, and trust in AI-assisted publishing flows. Better pipeline stability means fewer blocked drafts, faster refresh cycles, and stronger topical authority over time.
End-to-End Request Lifecycle
A request begins with one URL or a full playlist. The system normalizes input, validates payload shape, and creates queue jobs with deterministic identifiers. This keeps retries safe and reduces accidental duplicate exports.
Workers process each job in stages: caption retrieval, format transformation, quality checks, and artifact persistence. Every stage emits progress metadata so users can track status and recover partial failures without rerunning completed tasks.
The result is a traceable processing chain where each output can be mapped to source, transformation stage, and quality flags.
Design Principles We Keep Applying
- Prefer deterministic output contracts over implicit formatting.
- Keep failure domains small and isolated.
- Separate speed metrics from quality metrics.
- Treat quality metadata as a core output artifact.
- Build for replay and auditability at scale.
Engineering Validation Notes
- Architecture reflects production behavior under large batch workloads.
- Decisions prioritize fault isolation, throughput, and downstream data usability.
- Limitations of ASR-based tracks are documented instead of hidden behind marketing claims.
Quick FAQ
What is the main benefit of a decoupled queue architecture?
Why does clean TXT matter for LLM pipelines?
Related Reading
Automate Your Workflow
The unlimited bulk downloader and clean TXT output are live now. Stop manual copy work and save hours.
Try Bulk Downloader Now