Technical Documentation
Scaling AI with Clean Video Data
Transforming YouTube's unstructured dialogue into high-fidelity training corpora for Large Language Models (LLMs). Optimize your signal-to-noise ratio at an industrial scale.
Beyond Static Text: The Power of Conversational Data
In the current era of LLM development, the quality ofInstruction Fine-Tuning (IFT) data is more important than the raw volume of pre-training tokens. While Wikipedia and textbooks provide factual knowledge, they lack thenuance of human reasoning, multi-turn problem-solving, and domain-specific vernacularfound in professional YouTube content.
YouTube subtitles represent a "Conversational Gold Mine." However, standard extractors produce "Dirty Data"—saturated with timestamps, filler words, and broken syntax—which significantly degrades model perplexity.
The YTVidHub Sanitization Pipeline
Our extraction logic doesn't just "scrape"—it sanitizes. We handle the complex task of removing non-lexical artifacts to produce high-signal text datasets ready for tokenization.
Phase 01: Ingestion
Industrial-Scale Batch Processing
Researchers building domain-specific models (e.g., Legal AI or Medical LLMs) cannot afford manual data collection. YTVidHub Pro allows for concurrency-safe ingestion of thousands of video links.
Researcher Advantage
"Using YTVidHub, we reduced our data preparation time for our coding-assistant LLM by 85%. Extracting 1,200 hours of technical tutorials took minutes, not days."
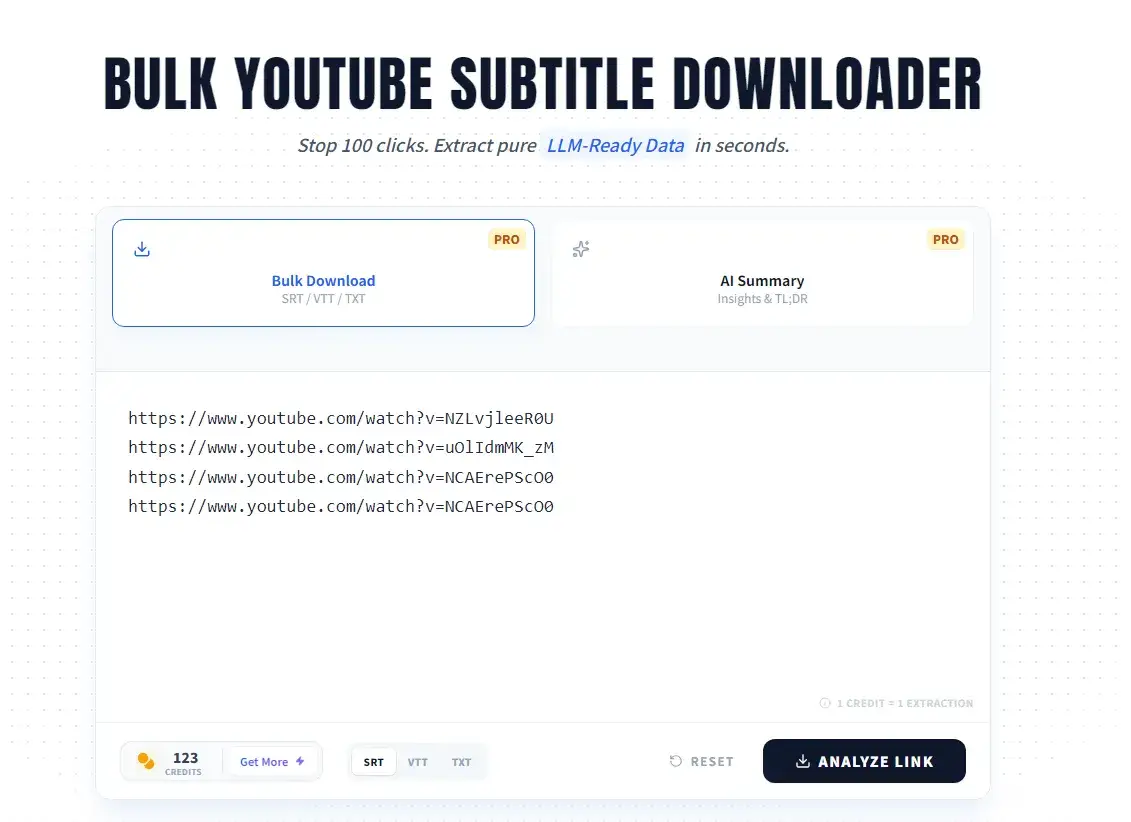
Phase 02: Sanitization
Maximizing Token Efficiency
Training on "dirty" transcripts wastes tokens and increases compute costs. Every "um," "uh," or timestamp is a token that costs money but provides zero semantic value. Our Clean Transcript Logic ensures every token contributes to the model's intelligence.
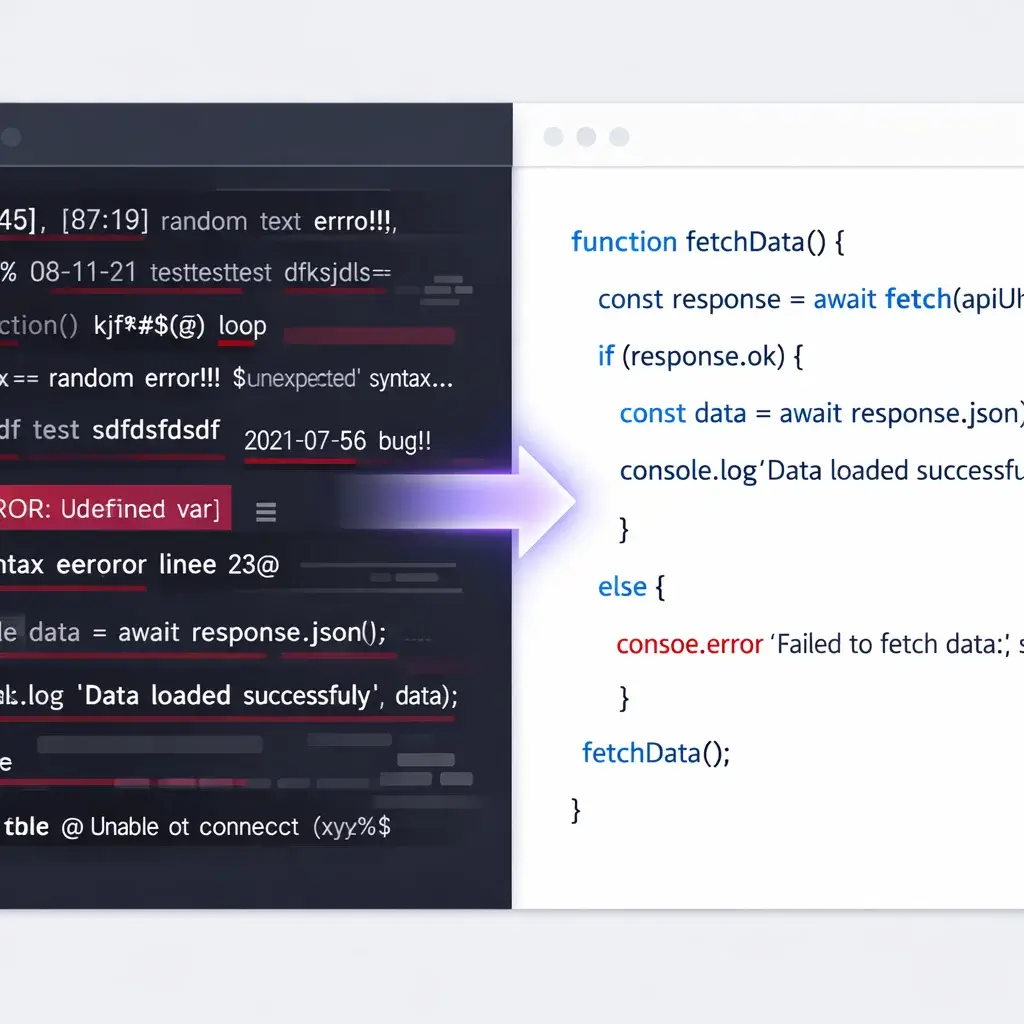
Ready for the Training Loop
We support modern data architectures. Whether you are usingSupervised Fine-Tuning (SFT) or building preference models for RLHF, our exports fit seamlessly into your pipeline.
Structured JSONL
Perfect for OpenAI, Anthropic, or Mistral API fine-tuning. Each video becomes an atomic object with metadata and clean content.
Pure Markdown / TXT
Ideal for RAG (Retrieval-Augmented Generation) systems. Native support for chunking and embedding in vector databases like Pinecone or Milvus.
Fuel Your Model Today
The difference between a "good" model and a "great" model is the data. Don't settle for noisy crawls.