Engineering Blog: Subtitle Data Prep
LLM Data Preparation Mastery Guide
Mastering bulk extraction, cleaning noisy ASR data, and structuring output for modern AI pipelines.
The Hidden Cost of Dirty Data
If you are looking to scale your LLM or NLP projects using real-world conversational data from YouTube, you know the hidden cost isn't just time—it's thequality of your training set.
We builtYTVidHubbecause generic subtitle downloaders fail at the critical second step: data cleaning. This guide breaks down exactly how to treat raw transcript data to achieve production-level readiness using ourbulk subtitle extraction tools.
Why Raw SRT Files Slow Down Your Pipeline
Many tools offer bulk download, but they often deliver messy output. For Machine Learning, this noise can be catastrophic, leading to poor model performance and wasted compute cycles.
Timestamp Overload
Raw SRT files are riddled with time codes that confuse tokenizers and inflate context windows unnecessarily.
Speaker Label Interference
Automatically inserted speaker tags (e.g., [MUSIC], [SPEAKER_01]) need removal or intelligent tagging.
Accuracy Discrepancies
The challenge of automatically generated subtitles requires a robust verification layer.
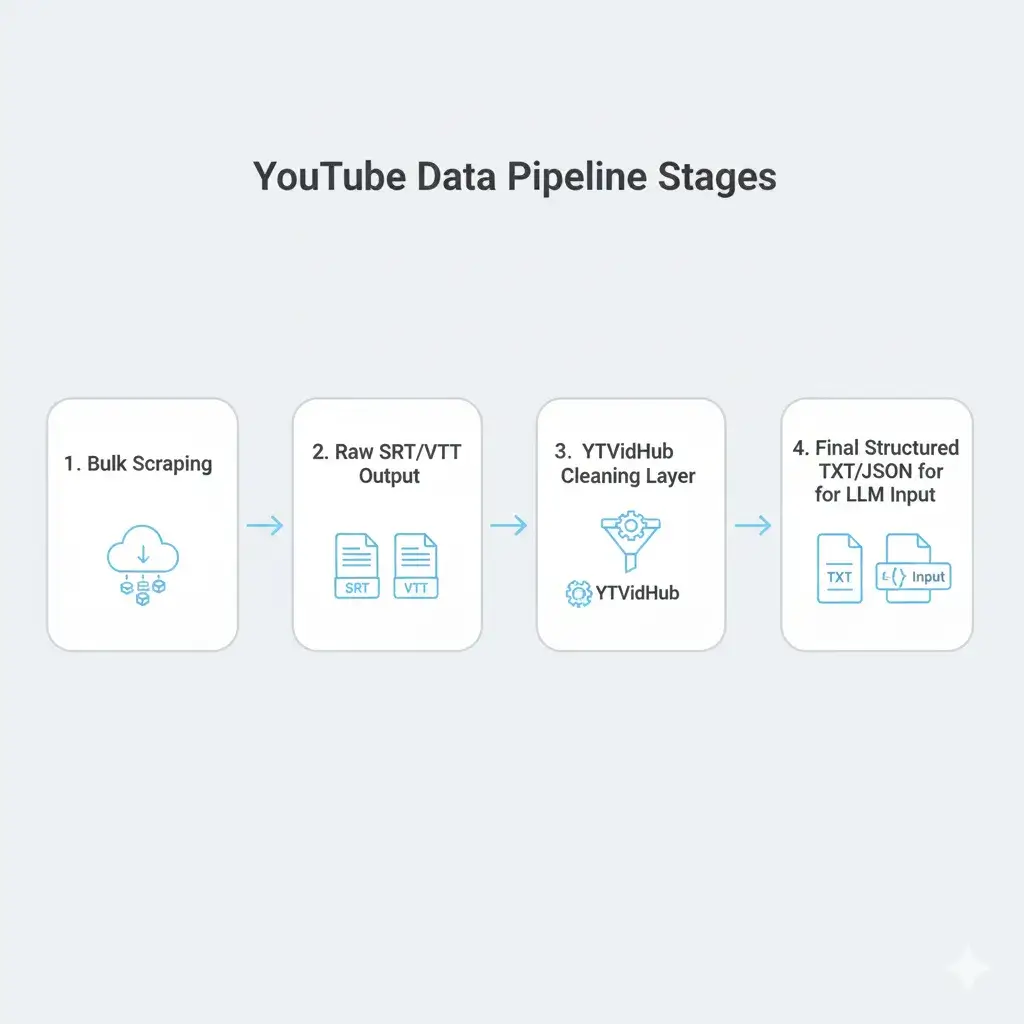
Figure 1: Production Pipeline Architecture
From Bulk Download to Structured Data
The key to efficiency is integrating the download and cleaning steps into a seamless pipeline. This is where a dedicated tool like ourYouTube subtitle downloadershines over managing complex custom scripts.
Format Analysis
Comparing SRT vs VTT vs TXT specifically for transformer-based model ingestion.
JSON Normalization
How we convert non-standard ASR output into machine-readable JSON structures.

Figure 2: Subtitle Format Comparison Matrix
Pro Tip from YTVidHub
"For most modern LLM fine-tuning, a clean, sequential TXT file (like our Research-Ready TXT) is superior to timestamped files. Focus on data density and semantic purity, not metadata overhead."
RAG Systems Application
One of the most powerful applications of clean, bulk transcript data is in building robust Retrieval-Augmented Generation (RAG) systems. By feeding a large corpus into a vector database, you can provide your LLM with real-time context.
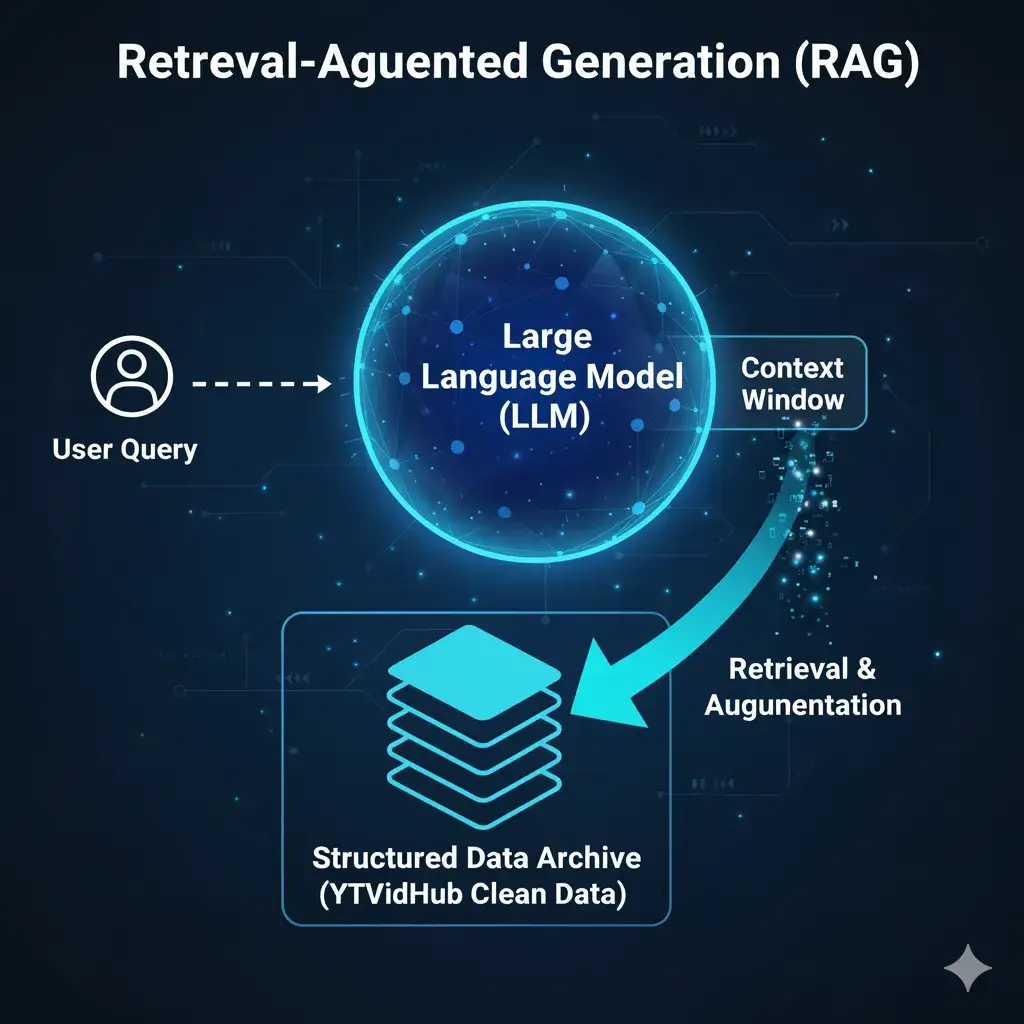
Figure 3: RAG Injection Architecture
Technical Q&A
Why is data cleaning essential for LLMs?
What is the best format for fine-tuning?
How do you handle ASR noise in YouTube transcripts?
What's the difference between SRT and clean TXT for AI training?
How much data do I need for effective LLM fine-tuning?
Can I use YouTube data for commercial AI applications?
Master Your Data Protocol
Join elite research teams using clean data for the next generation of LLMs. Industrial extraction starts here.
Optimized for: JSONL · CSV · TXT · PARQUET