Data Strategy
YouTube Subtitle Accuracy: Why Auto-Generated Captions Fail & How to Fix It
Auto-generated YouTube subtitles often contain errors that break downstream analysis. Learn why caption accuracy varies by language and how to validate subtitle quality before using it in research or AI pipelines.
By YTVidHub Engineering | Last reviewed Nov 2025
Quick Risk Summary
- Accessing subtitles is easier than validating subtitle quality.
- ASR errors can silently break sentiment, entity, and intent analysis.
- For production-grade datasets, run quality checks before model ingestion.
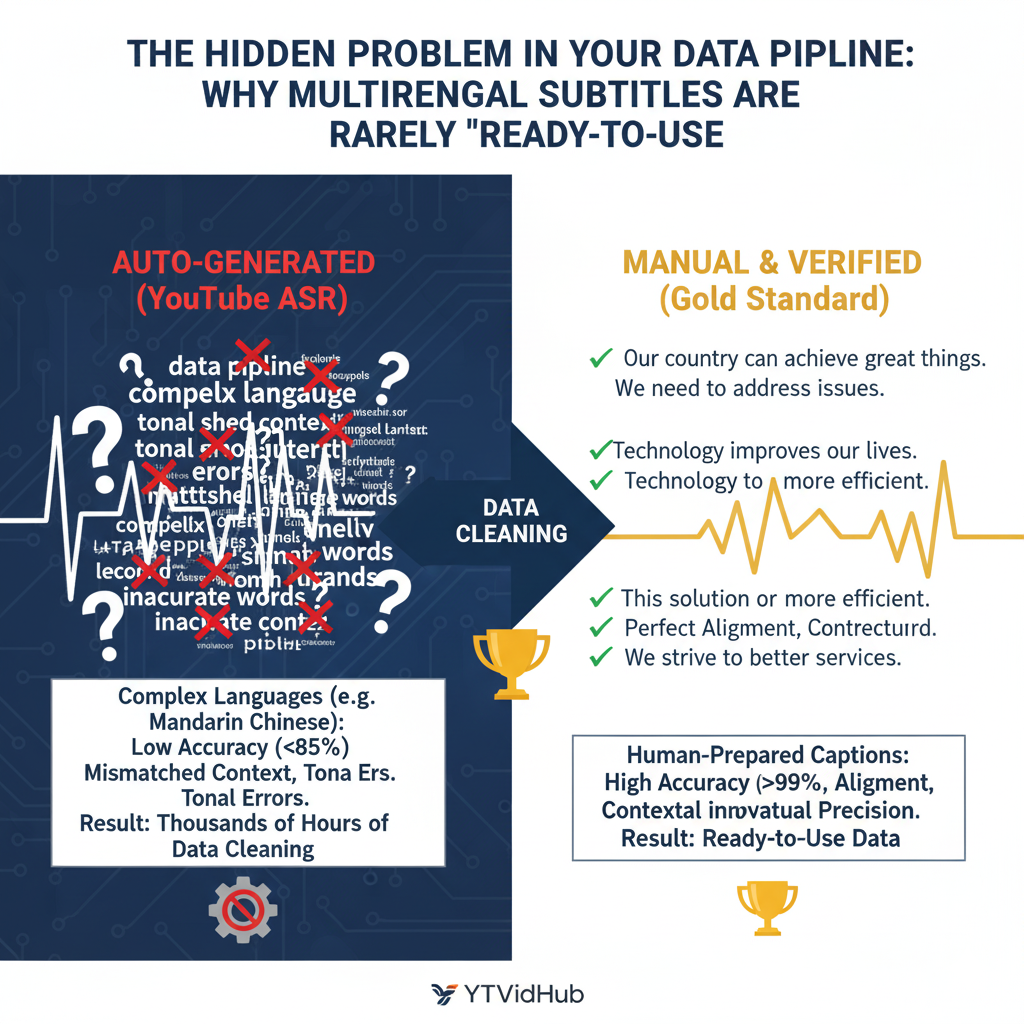
As the developer of YTVidHub, one of the most common questions we get is: "Do you support languages other than English?"The answer is yes.
Our batch YouTube subtitle downloader can access all available subtitle files provided by YouTube, including Spanish, German, Japanese, and Mandarin Chinese.
But download availability is not equal to dataset reliability. For researchers and analysts, quality inside the file is often the primary bottleneck.
Three Data Quality Tiers
Analysis quality depends on identifying the subtitle tier before ingestion.
Tier 1: Reliable Gold Standard
Manually uploaded captions prepared by creators. These are typically the strongest source for model training and research.
Tier 2: Unstable ASR Source
YouTube automatic speech recognition works well in some cases, but quality often degrades in niche, multilingual, or high-speed audio.
Tier 3: Error Multiplier
Auto-translated captions inherit ASR noise and then add translation artifacts. Avoid this tier for high-stakes work.
Subtitle Accuracy in Multilingual Pipelines
Most teams are not just asking whether subtitles are available. They need to decide whether a caption dataset is safe for model training, analytics, translation review, or public publishing.
Separate source types and failure modes before ingestion: manual captions, auto-generated ASR captions, and auto-translated captions. This structure helps teams estimate downstream risk before they invest in chunking, embedding, or retrieval pipelines.
The practical takeaway is simple: subtitle access is a logistics problem, subtitle accuracy is a quality-control problem. Treat them as separate gates in your workflow and your downstream model outputs become far more reliable.
Pre-Ingestion Quality Audit Checklist
- Sample 3-5 transcript segments against raw audio context.
- Measure named entity correctness on domain-specific terms.
- Flag non-speech noise ratio before sending to NLP pipelines.
- Mark low-confidence language tracks for manual review.
The Real Cost of Cleaning
Time saved in bulk download can be lost in post-cleaning if quality controls are skipped.
1. SRT Formatting Noise
SRT is optimized for playback, not analytics:
- • Timecode fragments (00:00:03 --> 00:00:06)
- • Sentence breaks split by timing windows
- • Non-speech tags like [Music] or (Laughter)
2. Garbage In, Garbage Out
Inaccurate transcripts produce inaccurate analytics. If core entities are misrecognized, your downstream sentiment, topic, and retrieval results can fail.
YouTube Auto-Generated Subtitle Accuracy by Language
Auto-generated subtitle accuracy varies significantly by language. English captions on clear audio typically reach 85-95% accuracy, but other languages often fall below 70%. Here is what researchers and developers should expect:
| Language | Typical Accuracy | Common Error Types | Safe for AI Training? |
|---|---|---|---|
| English | 85-95% | Homophones, technical terms, proper nouns | With review |
| Spanish | 75-88% | Regional accents, verb conjugation errors | With review |
| Japanese | 65-80% | Particle errors, kanji misrecognition | High risk |
| Arabic | 55-75% | Dialect confusion, right-to-left rendering | High risk |
| Hindi | 60-78% | Code-mixing with English, script errors | High risk |
| Mandarin | 60-80% | Tonal homophones, character substitution | High risk |
Because of this variance, a single global accuracy estimate is not enough. Track quality by language, source type, and domain context. A stream acceptable for light content review may still be unsafe for model training, sentiment analysis, or entity extraction pipelines.
The practical takeaway: separate access metrics from quality metrics. Fast download success does not guarantee reliable semantic output.
How to Check YouTube Subtitle Accuracy Before Using Data
Before feeding auto-generated subtitles into any analysis pipeline, run these quality checks to avoid garbage-in-garbage-out problems:
- 1
Spot-check 5-10 segments against the audio
Play random segments and compare spoken words with transcript text. Focus on technical terms, names, and numbers.
- 2
Measure named entity correctness
Check if brand names, people, places, and domain-specific terms are transcribed correctly. These errors are the most damaging for downstream analysis.
- 3
Flag non-speech noise ratio
Count [Music], (Laughter), and other non-speech tags. High noise ratios indicate the video is not suitable for text-based analysis.
- 4
Check sentence coherence
Auto-generated captions often split sentences at timing windows. Verify that sentence boundaries make logical sense for NLP processing.
Common YouTube Auto-Caption Error Patterns
Understanding the most common error types helps you build better validation rules and decide which subtitle tracks are safe to use:
Homophone Substitution
ASR systems frequently confuse words that sound alike: "their" vs "there", "affect" vs "effect", "to" vs "too". These errors are invisible when reading but change meaning in analysis.
Technical Vocabulary Mismatch
Domain-specific terms (medical, legal, tech jargon) are often misrecognized as common words. "API" becomes "a pie", "Kubernetes" becomes "cooper nets". Always validate technical content manually.
Timing-Induced Sentence Breaks
YouTube's caption system segments text by timing windows, not sentence structure. This creates mid-sentence breaks that confuse NLP parsers and reduce chunk quality for RAG pipelines.
Speaker Confusion in Multi-Speaker Videos
Auto-captions do not distinguish between speakers. In interviews, podcasts, or panel discussions, all text is merged into one stream, making attribution impossible without manual separation.
Remediation Loop for Better Subtitle Quality
- 1) Detect: sample representative transcript windows per language and channel class.
- 2) Classify: split formatting noise issues from true semantic errors.
- 3) Correct: apply glossary cleanup and manual review where quality gains are significant.
- 4) Validate: compare corrected output with source audio for high-risk segments.
- 5) Monitor: track quality drift and refresh thresholds as content mix changes.
Validation Notes
- Findings are based on repeated multilingual subtitle export and cleaning workflows.
- Quality tiers separate source reliability for practical data decisions.
- Limitations are explicit so teams can avoid hidden accuracy debt.
Frequently Asked Questions
Why are auto-generated subtitles often inaccurate in some languages?
Are auto-translated subtitles suitable for research datasets?
Related Reading
Building a Solution for Usable Data
We solve access first. Next, we continue improving accuracy and ready-to-use formats.
We are developing a Pro service for near human-level transcription. Meanwhile, try our playlist subtitle downloader for bulk processing.
Join Mailing List for Updates