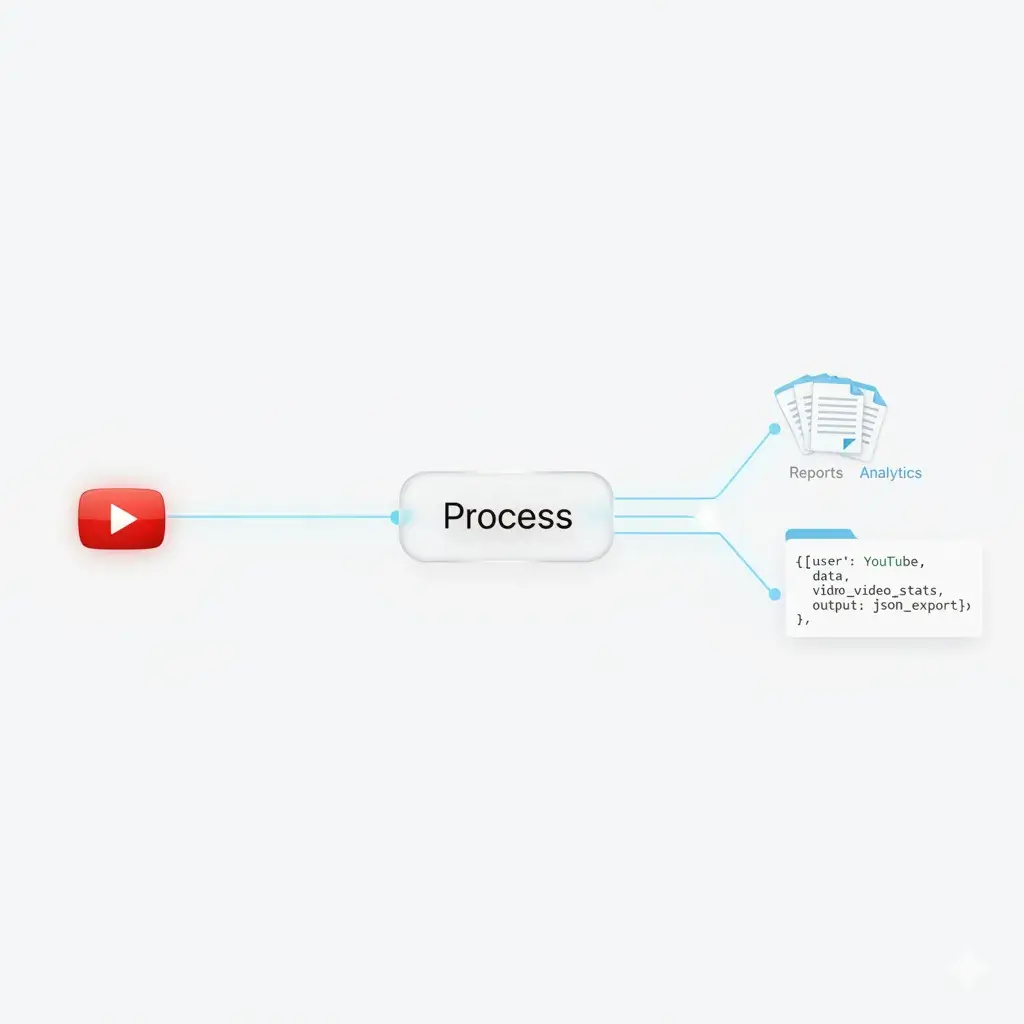
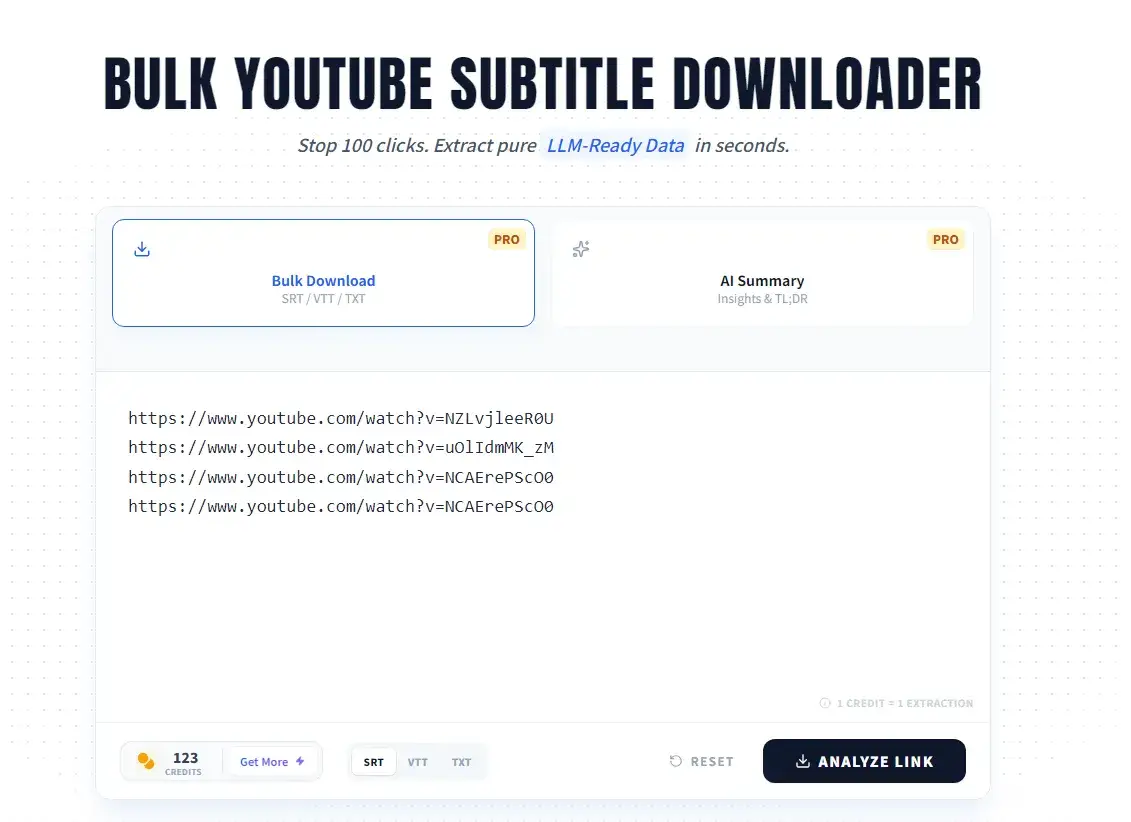
Beyond Static Text: The Power of Conversational Data
In the current era of LLM development, the quality of Instruction Fine-Tuning (IFT) data is more important than the raw volume of pre-training tokens. While Wikipedia and textbooks provide factual knowledge, they lack the nuance of human reasoning, multi-turn problem-solving, and domain-specific vernacular found in professional YouTube content.
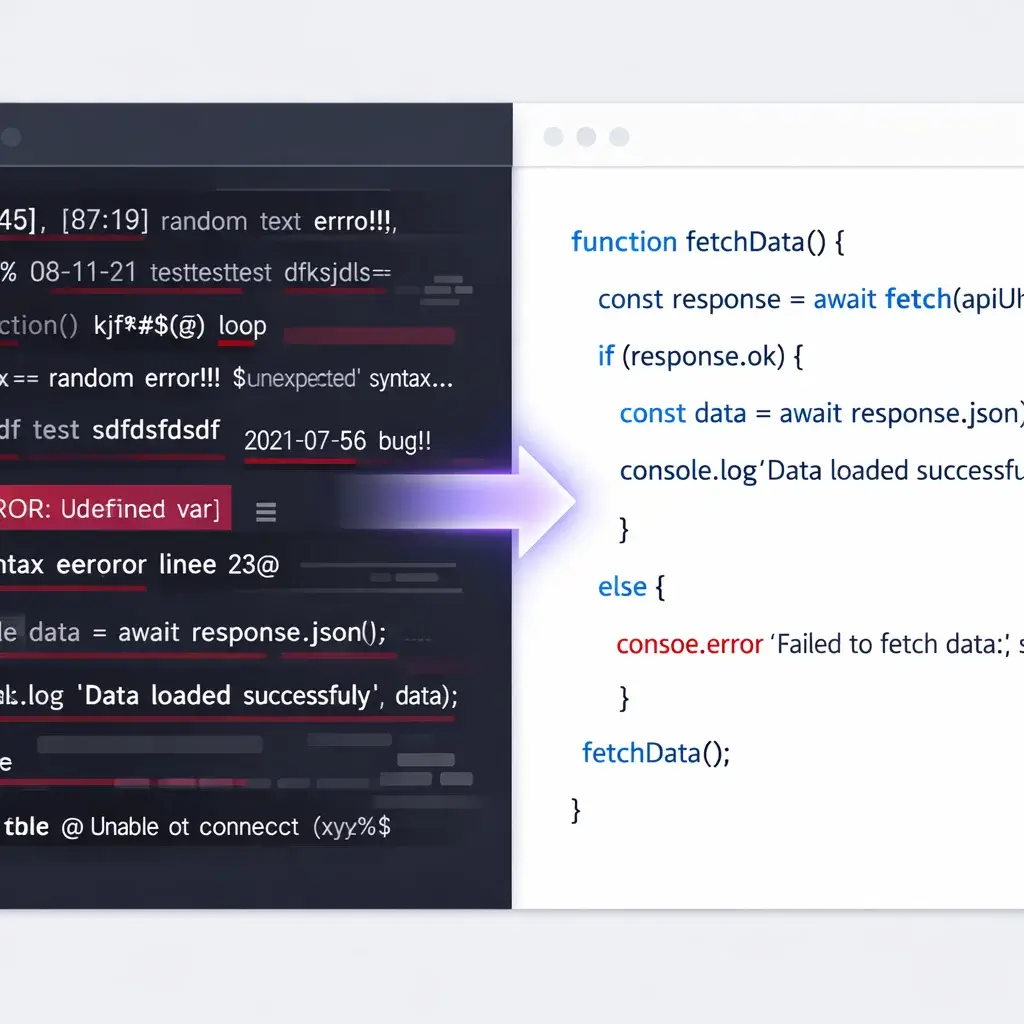
YouTube subtitles represent a "Conversational Gold Mine." However, standard extractors produce "Dirty Data"—saturated with timestamps, filler words, and broken syntax—which significantly degrades model perplexity.