The DNA of Digital Captions: SRT & WebVTT
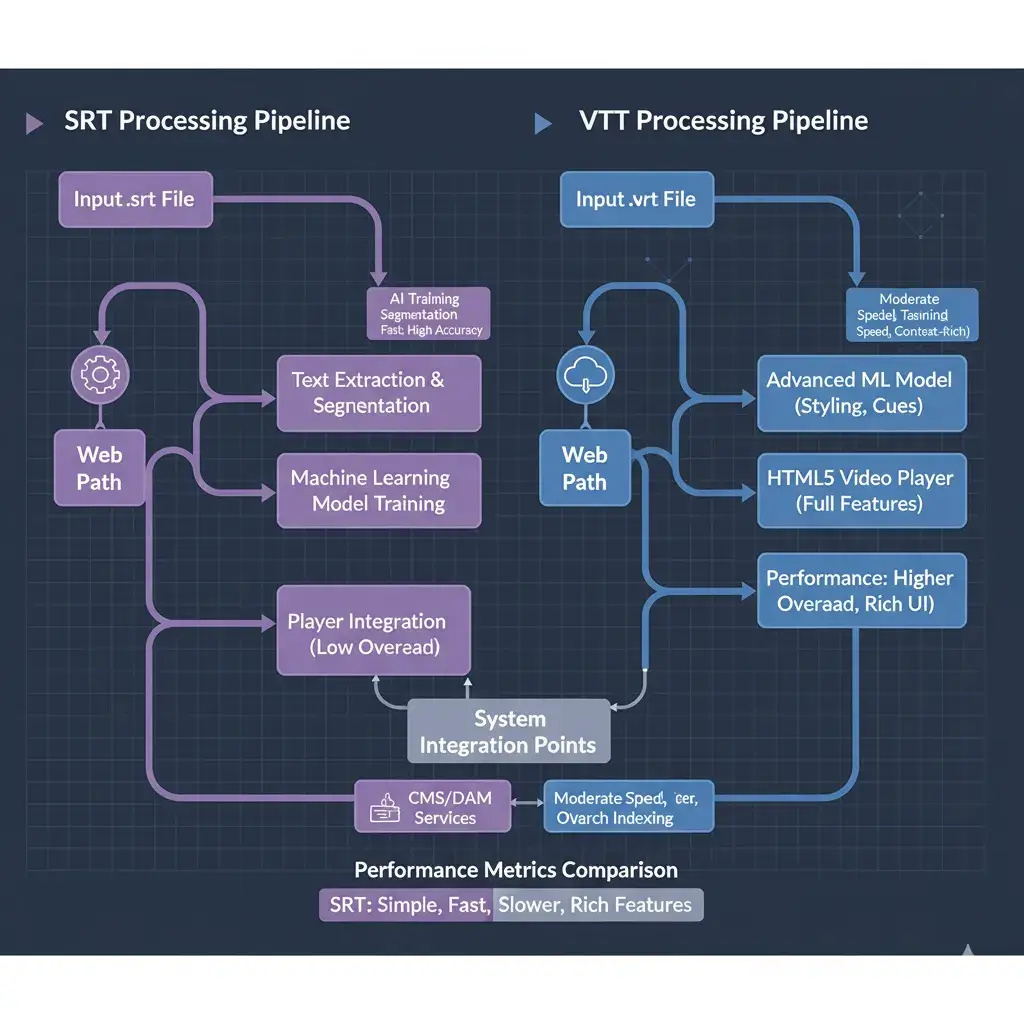
In the realm of subtitle data extraction for machine learning, the choice between SRT (SubRip) and WebVTT extends far beyond simple playback compatibility. SRT remains the universal standard for bulk transcription pipelines due to its minimalist, predictable structure. WebVTT, while essential for modern web accessibility, introduces CSS styling and metadata that can create noise in AI training datasets.
For AI/ML Researchers
SRT provides the cleanest dialogue corpus with maximum signal-to-noise ratio, essential for fine-tuning LLMs and building RAG systems.
For Web Developers
VTT enables rich, accessible video experiences with positioning, styling, and chapter markers for enhanced user engagement.