Why Your Current Workflow Is Inefficient
If you're a developer, researcher, or data scientist, you know that raw subtitle data from YouTube is useless. It's a swamp of ASR errors, messy formatting, and broken timestamps. This guide is for those who need advanced YouTube Subtitle Data Preparation—the tools and methods to convert noise into clean, structured data ready for LLMs, databases, and large-scale analysis.
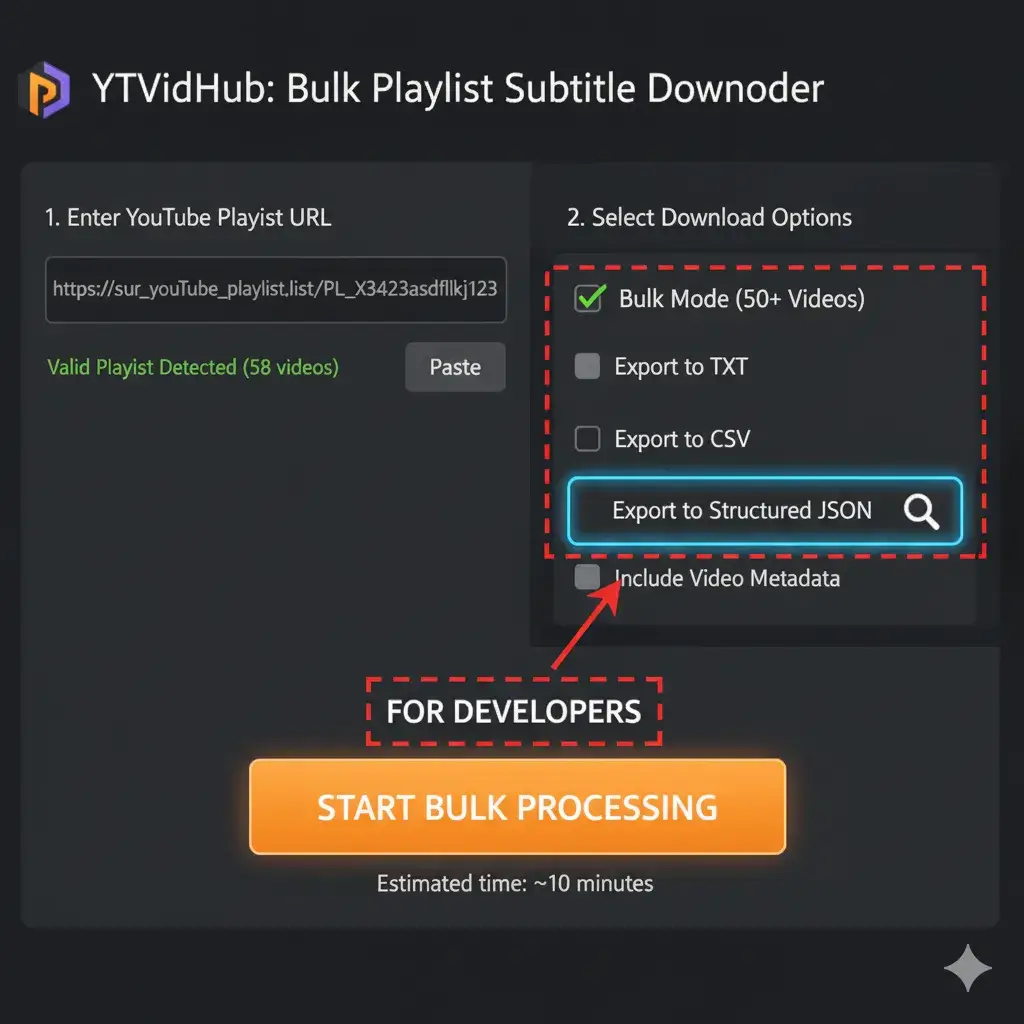
You cannot manually clean thousands of files. You also can't afford the YouTube Data API quota limits. If you need data from 50+ videos, you need batch processing. Our toolkit centers around resolving this efficiency bottleneck.
The Case for a Truly Clean Transcript
A YouTube transcript without subtitles is often just raw output riddled with errors. Our method ensures the final output is 99% clean, standardized text, perfect for training AI models.