The Hidden Cost of Dirty Data
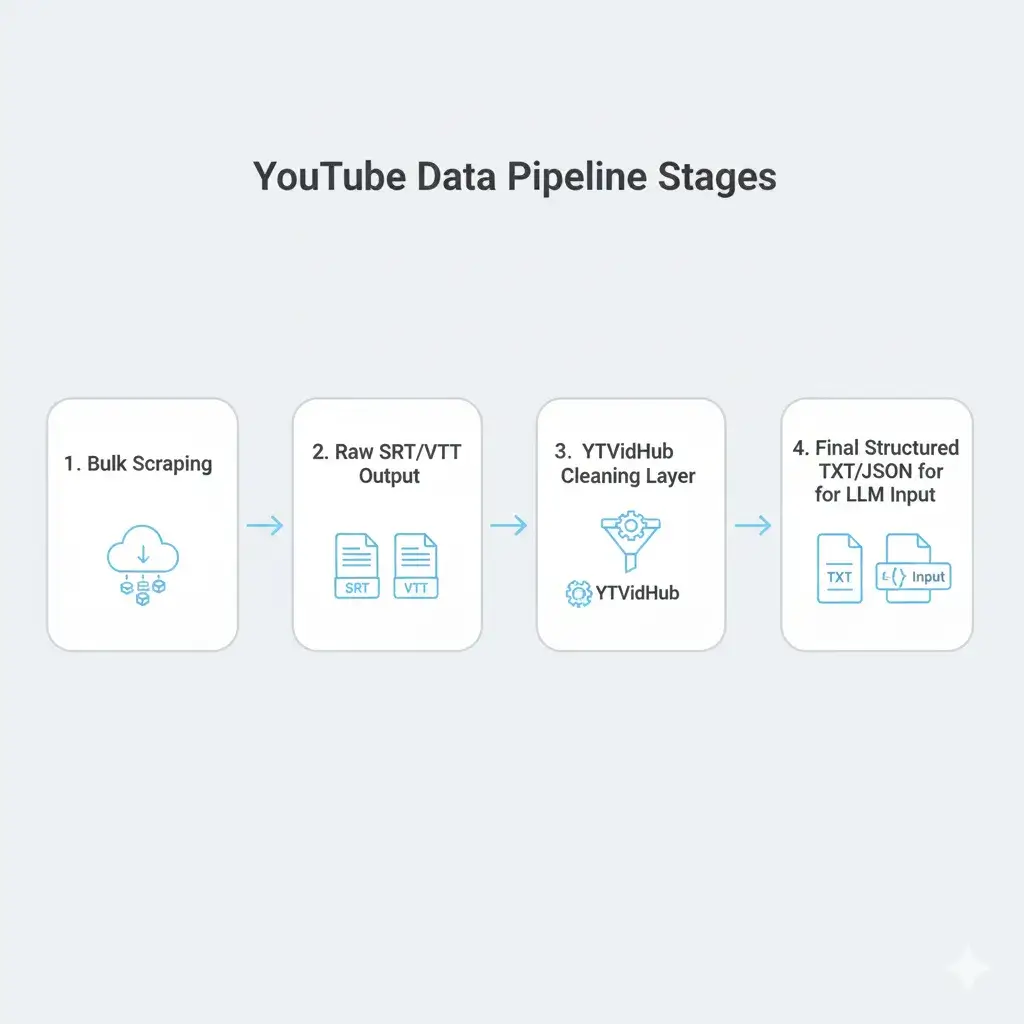
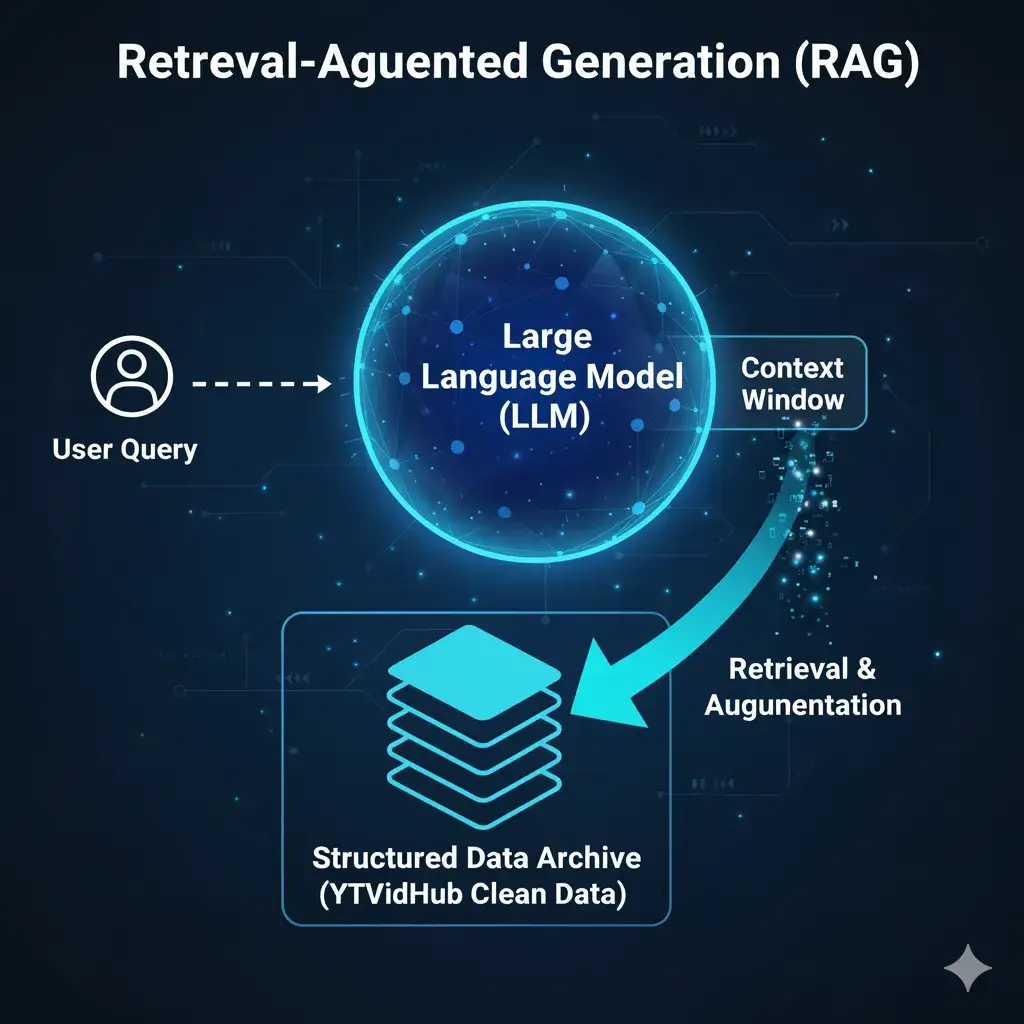
If you are looking to scale your LLM or NLP projects using real-world conversational data from YouTube, you know the hidden cost isn't just time—it's the quality of your training set.
We built YTVidHub because generic subtitle downloaders fail at the critical second step: data cleaning. This guide breaks down exactly how to treat raw transcript data to achieve production-level readiness using our bulk subtitle extraction tools.