As the developer of YTVidHub, we are frequently asked: "Do you support languages other than English?" The answer is a definitive Yes.
Our batch YouTube subtitle downloader accesses all available subtitle files provided by YouTube—Spanish, German, Japanese, and crucial languages like Mandarin Chinese.
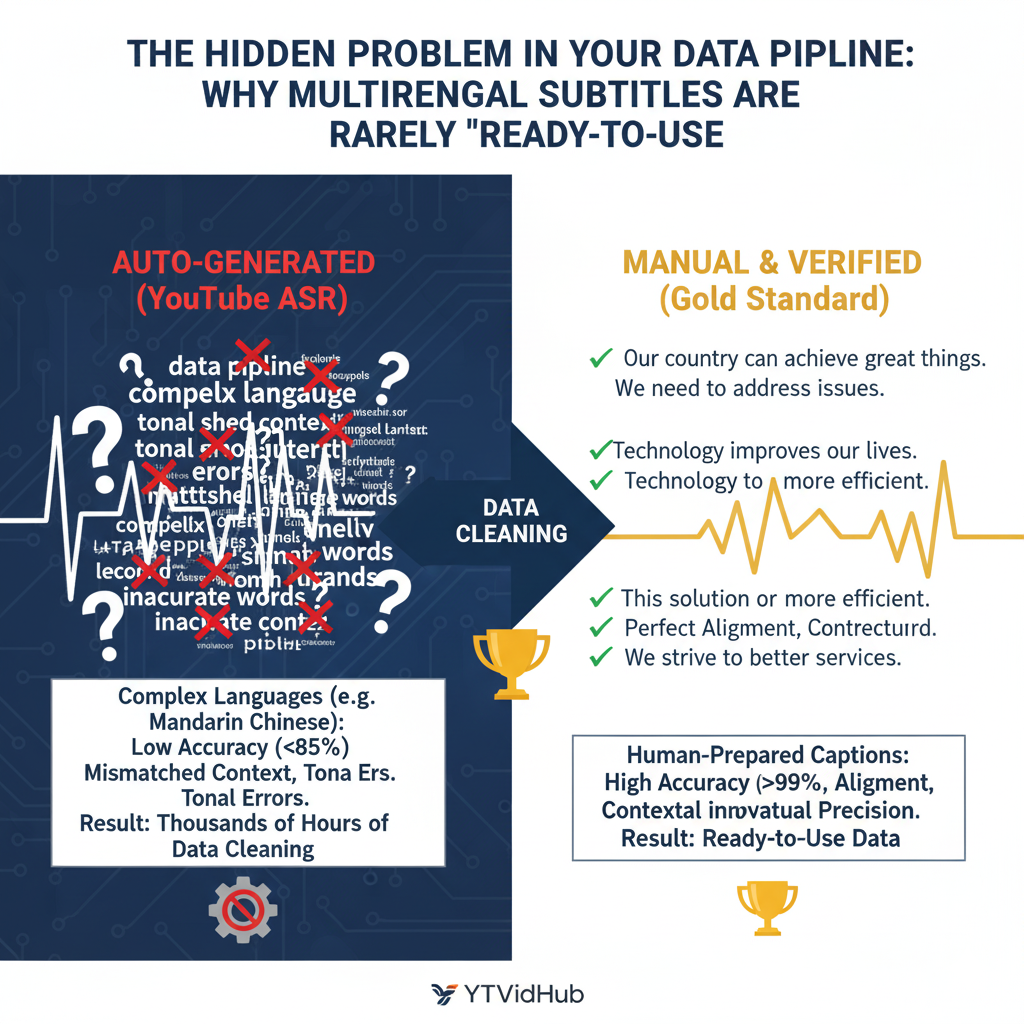
However, this comes with a major warning: The ability to download is not the same as the ability to use. For researchers and data analysts, the quality of the data inside the file creates the single biggest bottleneck in their workflow.